4. Analysis of feedforward loops
Design principles
The C1-FFL with AND logic has an on-delay, but no off-delay.
The C1-FFL with OR logic has an off-delay, but no on-delay.
The C1-FFL with both AND and OR logic can filter out short input impulses.
The I1-FFL with AND logic is a pulse generator and also speeds response compared to an unregulated circuit.
Concept
When multiple factors regulate a single gene, we need to specify the logic of the regulation, usually OR or AND.
[49]:
# Colab setup ------------------
import os, sys, subprocess
if "google.colab" in sys.modules:
cmd = "pip install --upgrade colorcet biocircuits watermark"
process = subprocess.Popen(cmd.split(), stdout=subprocess.PIPE, stderr=subprocess.PIPE)
stdout, stderr = process.communicate()
# ------------------------------
import numpy as np
import scipy.integrate
import biocircuits
import biocircuits.apps
import colorcet
colors = colorcet.b_glasbey_category10
import bokeh.io
import bokeh.layouts
import bokeh.models
import bokeh.plotting
# Set to True to have fully interactive plots
interactive_python_plots = False
notebook_url = "localhost:8888"
bokeh.io.output_notebook()
Finding 3-gene motifs in a bacterial transcriptional network
After three chapters, we have developed a toolbox of numerical, analytical, and plotting-based approaches, and applied them to various single-gene and two-gene circuits. In the last chapter, we discussed a toggle switch that generates bistability via mutual repression by two repressor proteins. We will now move on to systems with more components and greater functional complexity, starting with three-component circuits.
There are thirteen different ways in which three transcription factors can regulate one another, as diagrammed below. Which ones should we analyze first? A sensible choice is to again look toward natural gene regulatory networks and ask which of these potential circuits are overrepresented in natural circuits, i.e. which (if any) of these are network motifs, which are, as a reminder, statistically over-represented circuits in natural networks (circuits).
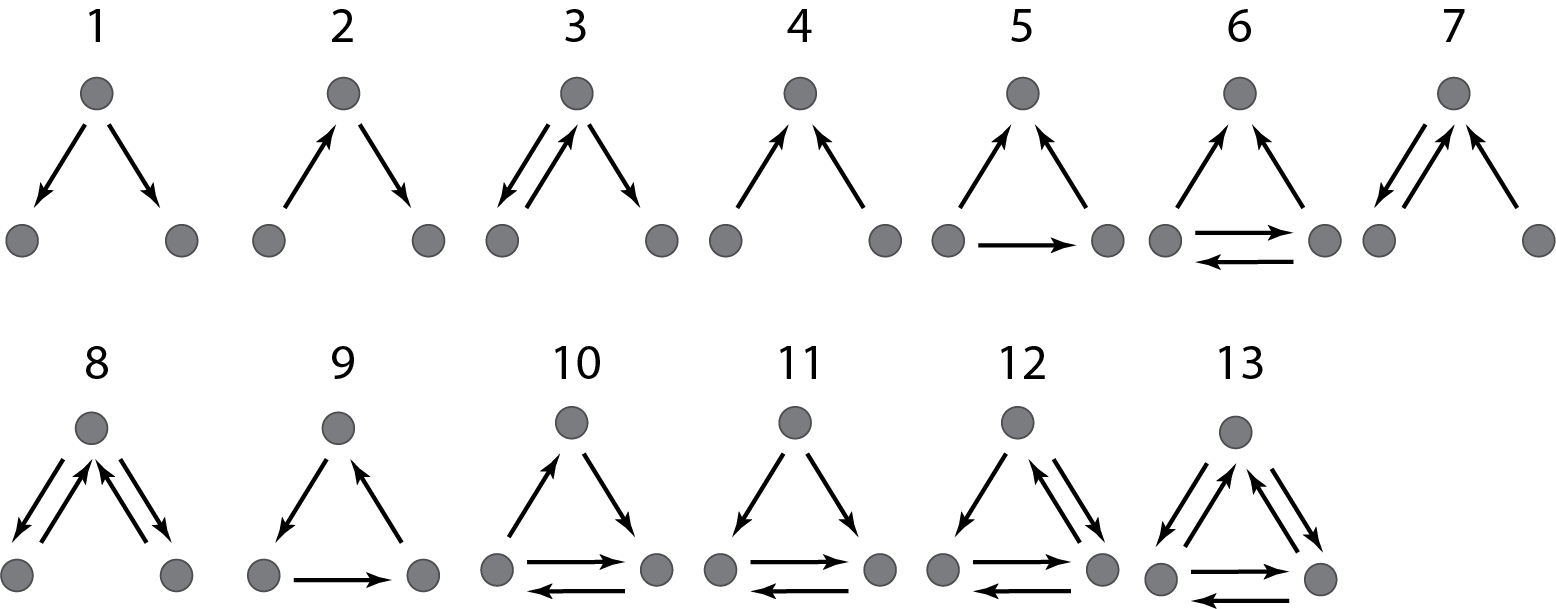
Image adapted fromMilo, et al., 2002.
Milo and coworkers (Milo, et al., 2002) performed just such an analysis. The authors then tabulated the number of times that each of these thirteen regulatory patterns in maps of natural transcriptional circuits. But a question remains— how often would one expect to see any one of these given patterns within a circuit of that size? In order to answer this question, a null model for a network is required. We hinted at this concept in Chapter 2, and here we go into more detail.
Random graphs enable motif identification
Consider a directed graph representing a hypothetical regulatory circuit (left). As before, each numbered node in this network represents an operon or transcription factor, and arrows indicate regulation of the target node by a transcription factor in the source node. To find over-represented patterns in this graph, we can compare it to an ensemble of randomized variants and look for sub-graphs that occur more frequently in the real circuit than in the random variants.
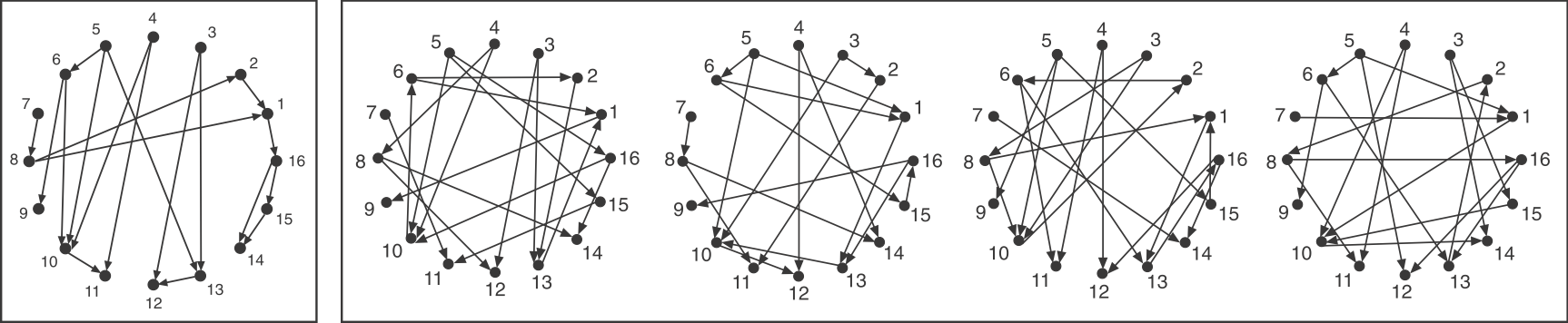
Schematic comparison between a specific circuit (left) and a set of randomized variants with the same incoming and outgoing arrow distributions (right). Image modified fromMilo et al, Science, 2002.
To make the comparison as fair as possible, we need to design variant graphs that maintain the key statistical properties of the original graph. Specifically, we insist that all variant graphs have the same number of nodes and arrows. But this is not really enough: It would not make sense to compare a graph whose arrows are distributed over all the nodes to a variant in which, say, all arrows stem from a single source node, or converge on a single target node. We therefore need to impose a stronger constraint: all variant graphs should maintain the exact distribution of incoming and outgoing arrows for each node.
If you examine the graphs above, you can see that they were constructed to have the same numbered nodes. Furthermore, the number of arrows exiting and entering each numbered node is exactly the same in all graphs. For example, node 4 always has 2 outgoing arrows. Node 6 always has one incoming and two outgoing arrows, node 12 always has 2 incoming arrows, and so on.
To generate the randomized graphs, imagine cutting each arrow in half with a scissors to generate a dangling “+” end connected to an arrowhead and a dangling “–” end connected to a source node. Then imagine tying each “+” end to a randomly chosen “–” end. Voila, we have a new randomized graph, guaranteed through this procedure to maintain the same joint distribution of incoming and outgoing arrows. For more details, see the algorithms in Shen-Orr et al, 2002 and in Newman et al, 2001.
The feedforward loop is overrepresented in natural transcriptional networks
Now that we understand how to formulate a proper null model for motif identification, we return to the analysis by Milo, et al. The authors used a z-score to quantify over- or under-representation in units of the standard deviation of the number of occurrences for the sub-graph in the randomized circuits,
\begin{align} z = \frac{n_{obs}-\langle n\rangle}{\sigma}, \end{align}
where \(n_{obs}\) is the number of times the sub-graph was observed in the actual circuit, \(\langle n\rangle\) is the mean number of times it was observed in randomized circuits, and \(\sigma = \sqrt{\langle (n-\langle n \rangle)^2\rangle}\) is the standard deviation of the number of times it was observed in randomized circuits.
They did this for several transcriptional circuits, including E. coli, yeast (two versions), and B. subtilis. In the plot below (data digitized from Milo, et al., 2004), the four networks are so similar in their z-score profiles that the different organisms overlap almost perfectly.
[50]:
x = np.array([1, 4, 2, 7, 3, 8, 5, 9, 11, 6, 10, 12, 13])
z_ecoli = np.array([-0.5, -0.5, -0.5, 0, 0, 0, 0.5, 0, 0, 0, 0, 0, 0])
z_yeast_1 = np.array([-0.5, -0.5, -0.5, 0, 0, 0, 0.5, 0, 0, 0, 0, 0, 0])
z_yeast_2 = np.array([-0.5, -0.5, -0.5, 0, 0, 0, 0.5, 0, 0, 0, 0, 0, 0])
z_bacillus = np.array([-0.5, -0.5, -0.5, 0, 0.032, 0, 0.5, 0, 0, 0, 0, 0, 0])
p = bokeh.plotting.figure(
frame_width=500,
frame_height=100,
x_axis_label="motif",
y_axis_label="normalized z-score",
x_range=[0, 14],
y_range=[-1.0, 0.7],
tools="save",
)
p.xgrid.grid_line_color = None
p.ygrid.grid_line_color = None
p.xaxis.ticker = bokeh.models.tickers.FixedTicker(ticks=x)
p.yaxis.ticker = bokeh.models.tickers.FixedTicker(ticks=[-0.5, 0, 0.5])
p.ray(0, 0, color='black', line_width=1)
p.ray(0, 0, angle=-np.pi, color='black', line_width=1)
ecoli = p.scatter(x, z_ecoli, fill_alpha=0, size=10)
yeast_1 = p.square(x, z_yeast_1, fill_alpha=0, size=10, color=colors[1])
yeast_2 = p.diamond(x, z_yeast_2, fill_alpha=0, size=12, color=colors[2])
bacillus = p.star(x, z_bacillus, fill_alpha=0, size=10, color=colors[3])
items = [("E. coli", [ecoli]), ("yeast 1", [yeast_1]), ("yeast 2", [yeast_2]), ("B. subtilis", [bacillus])]
legend = bokeh.models.Legend(items=items)
legend.click_policy = "hide"
p.add_layout(legend, 'right')
bokeh.io.show(p)
As you can see, one particular motif, number 5, is overrepresented in all of the transcriptional networks, number 7:
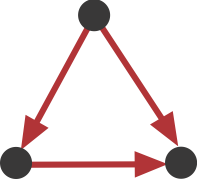
This sub-graph, termed the feed-forward loop (FFL), has one node that regulates a target node two ways: directly, and indirectly through the third node.
Several features are striking from their results:
There is strong over-representation of feed-forward loops (FFLs). In E. coli, one expects to see 7±5 FFLs by chance, but one observes this pattern 42 times in the real circuit.
The over-representation of FFLs is conserved across three distinct organisms, suggesting it is a general property of transcriptional circuits.
Most other sub-graphs are neither over- nor under-represented.
Three sub-graphs are statistically under-represented. They occur significantly less often than one would expect by chance, provoking the question of what problems they might present as components of larger circuits. These three sub-graphs are all sub-graphs of the FFL sub-graph. Thus, it is not that, e.g., divergent regulation (represented by sub-graph 1) is rare; it is just that when it does occur, it does so in the context of the FFL.
There are many kinds of FFLs
Our description of regulatory interactions in the FFL so far has been oversimplified in several ways:
We have not distinguished between positive regulation (activation) and negative regulation (repression).
We have not considered how multiple regulators combine to control expression of a mutual target operon.
We have ignored the quantitative aspects of regulation.
Understanding the biological function of a motif requires thinking about these aspects more carefully.
To address the first point, we can classify the overall FFL motif into \(2^3=8\) different categories depending on which of its 3 arrows are positive or negative:
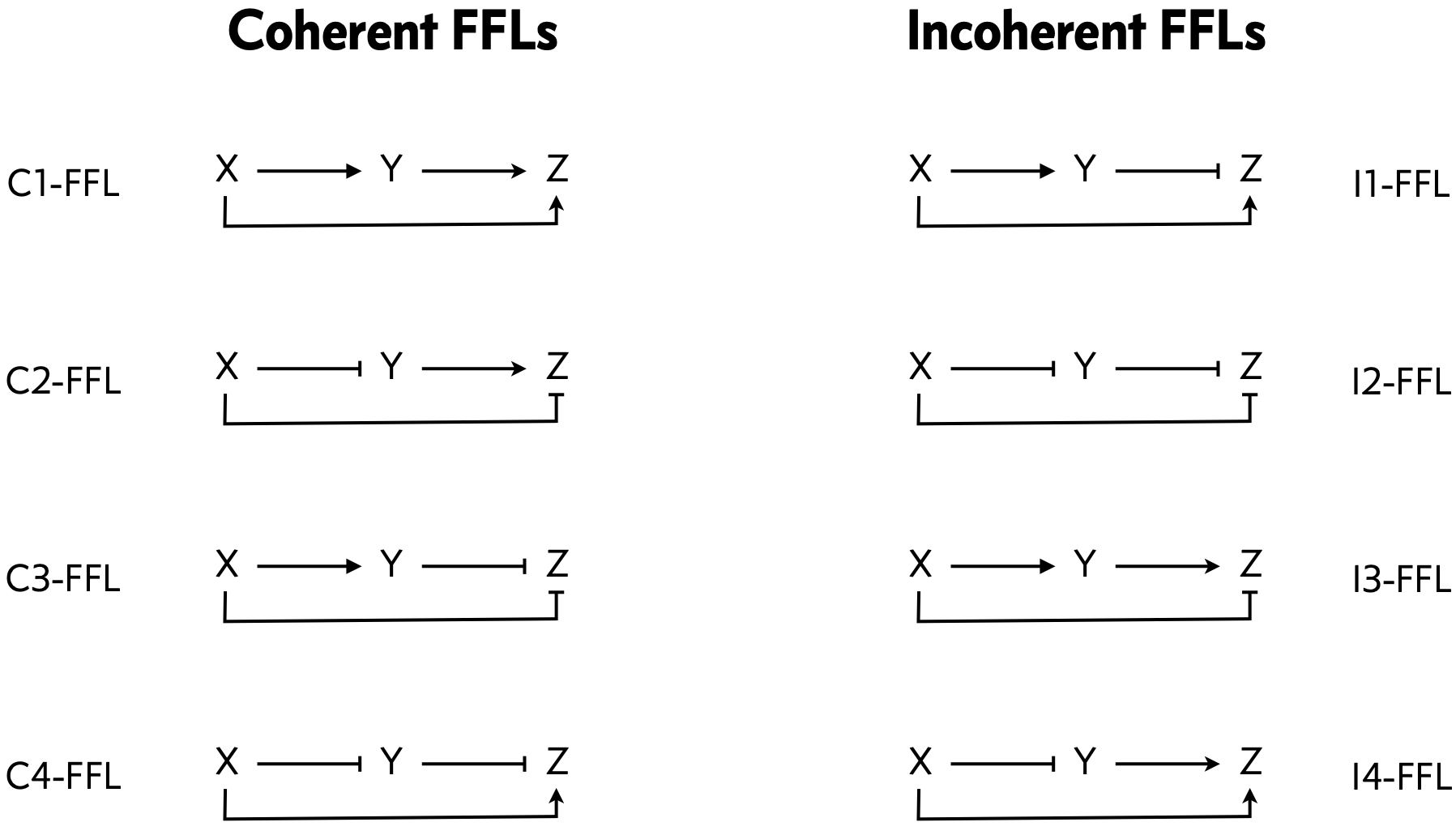
In this classification, half of the FFL architectures are coherent, meaning that X’s direct regulation of Z and its indirect regulation of Z are of the same type, both activating or both repressing. the other half are incoherent, meaning that the direct and indirect regulatory paths have the opposite sign.
We can further sub-classify the FFLS, according to how the regulatory arrows converging on the third node (now labeled “Z”) combine. Consider first the example where both X and Y activate Z, as in the C1-FFL and I4-FFl. In AND regulation, both X and Y need to be simultaneously present at high levels for Z to be expressed. In OR regulation, either input being at a high level is sufficient to activate Z. We will discuss this logic in more detail momentarily.
Now that we have defined what FFLs are and how we can represent them, we will spend the rest of this chapter (and even some beyond) considering what functions the various FFLs can perform for cells.
The most-encountered FFLs
While FFLs in general are motifs, some FFLS are more often encountered than others. In the figure below, using data taken from a review by Uri Alon, we see relative abundance of the eight different FFLs in E. coli and S. cerevisiae. Two FFLs, C1-FFL and I1-FFL, stand out as having much higher abundance than the other six. We will focus our study on these two in this chapter.
[51]:
# Data based on Alon, Nature Rev. Genet., 2007, https://doi.org/10.1038/nrg2102
species = ["yeast", "E. coli"]
ffls = reversed(["C1 ", "C2 ", "C3 ", "C4 ", "I1 ", "I2 ", "I3 ", "I4 "])
data = {
"species": species,
"E. coli": reversed([0.464, 0.09, 0, 0, 0.374, 0.055, 0.017, 0]),
"yeast": reversed([0.377, 0.035, 0.105, 0.08, 0.28, 0.027, 0.052, 0.044]),
}
x = [(ffl, sp) for ffl in ffls for sp in species]
frac = sum(zip(data["E. coli"], data["yeast"]), ())
source = bokeh.models.ColumnDataSource(data=dict(x=x, frac=frac))
p = bokeh.plotting.figure(
y_range=bokeh.models.FactorRange(*x),
frame_height=450,
title="Relative abundance of FFLs",
)
p.hbar(
y="x",
left=0,
right="frac",
height=0.9,
source=source,
fill_color=bokeh.transform.factor_cmap(
"x", palette=colors, factors=species, start=1, end=2
),
line_color="white",
)
p.x_range.start = 0
p.y_range.range_padding = 0.05
p.yaxis.group_label_orientation = "horizontal"
p.ygrid.grid_line_color = None
bokeh.io.show(p)
Logic of regulation by two transcription factors
Because X and Y both regulate Z in an FFL, we need to specify how they collaborate in the regulation.
For the sake of illustration, let us assume we are discussing C1-FFL, where X activates Z and Y also activates Z. One can imagine a scenario where both X and Y need to be present to turn on Z. For example, they could be binding partners that together serve to recruit polymerase to the promoter. We call this AND logic. In other words, to get expression of Z, we must have X AND Y. Conversely, if either X or Y may each alone activate Z, we have OR logic. That is, to get expression of Z,
we must have X OR Y.
So, to fully specify an FFL, we need to also specify the logic, either AND or OR, of how Z is regulated. Including choice of logic gives a total of 16 possible FFLs.
We are now left with the task of figuring out how to mathematically encode AND and OR logic. Before doing so, we note that, as discussed previously, we are using Hill functions, which are phenomenological functions describing how effectors may regulate gene expression capturing both the necessary concentration of effector (\(k\)) and the ultrasensitivity of the regulation (\(n\)). When the molecular details of the regulation mechanics of an effector are known, we may derive the appropriate functions describing gene expression regulation rather than using Hill function. Similarly, for two effectors, we could also derive the functions from the molecular details and discover what kind of logic emerges. See, for example, this 2005 paper by Bintu and coworkers. We often do not know the molecular details, and Hill functions and the two-effector variants thereof we present below are quite useful in analyzing the properties of circuit architectures.
We now proceed to formally write mathematical expressions for the dynamics of a gene product Z under regulatory control of effectors X and Y. The dynamics of the concentration of Z may be written as
\begin{align} \frac{\mathrm{d}z}{\mathrm{d}t} = \beta \,f(x, y) - \gamma z, \end{align}
where the lowercase letters denote the concentrations of the respective species.
Our goal is to specify the dimensionless regulatory function \(f(x, y)\) that encodes how X and Y may together regulate Z. Our approach is to assign a “weight” to each state of a promoter region. With two effectors, X and Y, the promoter region could be unbound, bound with X, bound with Y, or bound with both X and Y. To get the regulatory function, we sum the weights of states that allow polymerase binding and divide by the sum of all weights. This gives the fraction of time that expression of the gene is “on.” For example, if X and Y are both activators and they together have AND logic, we have
\begin{align} f(x, y) = \frac{\text{X and Y bound weight}}{(\text{unbound weight}) + (\text{X bound weight}) + (\text{Y bound weight}) + (\text{X and Y bound weight})} \end{align}
The weights are chosen to give Hill-like functions.
promoter region state |
weight |
dimensionless weight |
|---|---|---|
unbound |
\[1\]
|
\[1\]
|
X bound |
\[(x/k_x)^{n_x}\]
|
\[x^{n_x}\]
|
Y bound |
\[(y/k_y)^{n_y}\]
|
\[y^{n_y}\]
|
X and Y bound |
\[(x/k_x)^{n_x}\,(y/k_y)^{n_y}\]
|
\[x^{n_x}\,y^{n_y}\]
|
The dimensionless weights are given by substituting \(x \leftarrow x/k_x\) and \(y \leftarrow y/k_y\). We will use the dimensionless versions of these functions henceforth. We note that the denominator of the regulatory function \(f(x,y)\) is always the same,
\begin{align} 1 + x^{n_x} + y^{n_y} + x^{n_x} y^{n_y} = (1 + x^{n_x})(1 + y^{n_y}). \end{align}
Alternatively, we could have a structure where maximally only one of the two effectors may be bound at a time (for example due to steric reasons), in this case the states and weights are given in the table below.
promoter region state |
weight |
dimensionless weight |
|---|---|---|
unbound |
\[1\]
|
\[1\]
|
X bound |
\[(x/k_x)^{n_x}\]
|
\[x^{n_x}\]
|
Y bound |
\[(y/k_y)^{n_y}\]
|
\[y^{n_x}\]
|
In this case, the denominator for all of the regulatory functions is \(1 + x^{n_x} + y^{n_y}\). We will refer to such regulatory functions as corresponding to “single occupancy.”
With this prescription, let us proceed to write the regulatory functions \(f(x, y)\) for various architectures.
Logic with two activators
Let us start first with X and Y, both activating, with AND logic, as seen in the C1-FFL and I4-FFL. To help conceptualize how the logic translates into expression of Z before we get into the mathematical expressions, we can construct a truth table for whether or not Z is on, given the on/off status of X and Y. The truth table is shown below, with a zero entry meaning that the gene is not on and a one entry meaning it is on.
X |
Y |
Z |
|---|---|---|
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
1 |
1 |
We can also construct a truth table for OR logic with X and Y both activating.
X |
Y |
Z |
|---|---|---|
0 |
0 |
0 |
0 |
1 |
1 |
1 |
0 |
1 |
1 |
1 |
1 |
Following the above prescription, the dimensionless regulatory functions are
\begin{align} &\text{AND logic: } f(x,y) = \frac{x^{n_x} y^{n_y}}{(1 + x^{n_x})(1 + y^{n_y})},\\[1em] &\text{OR logic: } f(x,y) = \frac{x^{n_x} + y^{n_y} + x^{n_x} y^{n_y}}{(1 + x^{n_x})(1 + y^{n_y})}. \end{align}
If only single-occupancy is allowed, the gene can never be activated with AND logic, and the regulatory function with OR logic is
\begin{align} &\text{OR logic (single occupancy): } f(x,y) = \frac{x^{n_x} + y^{n_y}}{1 + x^{n_x} + y^{n_y}}. \end{align}
We can make plots of these regulatory functions to demonstrate how they represent the respective logic. To accentuate the logic, we will choose very sharp Hill functions \(n_x = n_y = 20\).
[52]:
def xyz_im_plot(x, y, z, x_log, y_log, z_log, title=None, palette="Viridis256"):
"""Display x, y, z data as an image."""
p_log = bokeh.plotting.figure(
frame_height=200,
frame_width=200,
x_range=(x_log.min(), x_log.max()),
y_range=(y_log.min(), y_log.max()),
x_axis_label="x",
y_axis_label="y",
title=title,
toolbar_location=None,
x_axis_type="log",
y_axis_type="log",
)
p_log.image(
image=[z_log],
x=x_log.min(),
y=y_log.min(),
dw=x_log.max() - x_log.min(),
dh=x_log.max() - x_log.min(),
palette=palette,
alpha=0.8,
)
p = bokeh.plotting.figure(
frame_height=200,
frame_width=200,
x_range=(x.min(), x.max()),
y_range=(y.min(), y.max()),
x_axis_label="x",
y_axis_label="y",
title=title,
toolbar_location=None,
)
p.image(
image=[z],
x=x.min(),
y=y.min(),
dw=x.max() - x.min(),
dh=x.max() - x.min(),
palette=palette,
alpha=0.8,
)
p_log.visible = True
p.visible = False
radio_button_group = bokeh.models.RadioButtonGroup(
labels=["log", "linear"], active=0, width=100
)
col = bokeh.layouts.column(
p_log, p, bokeh.layouts.row(bokeh.models.Spacer(width=100), radio_button_group)
)
radio_button_group.js_on_change(
"active",
bokeh.models.CustomJS(
args=dict(p_log=p_log, p=p),
code="""
if (p_log.visible == true) {
p_log.visible = false;
p.visible = true;
}
else {
p_log.visible = true;
p.visible = false;
}
""",
)
)
return col
# Get x and y values for plotting
x_log = np.logspace(-2, 2, 200)
y_log = np.logspace(-2, 2, 200)
x = np.linspace(0, 2, 200)
y = np.linspace(0, 2, 200)
xx, yy = np.meshgrid(x, y)
xx_log, yy_log = np.meshgrid(x_log, y_log)
# Parameters (steep Hill functions)
nx = 20
ny = 20
# Generate plots
p_and = xyz_im_plot(
xx,
yy,
biocircuits.aa_and(xx, yy, nx, ny),
xx_log,
yy_log,
biocircuits.aa_and(xx_log, yy_log, nx, ny),
title="two activators, AND logic",
)
p_or = xyz_im_plot(
xx,
yy,
biocircuits.aa_or(xx, yy, nx, ny),
xx_log,
yy_log,
biocircuits.aa_or(xx_log, yy_log, nx, ny),
title="two activators, OR logic",
)
p_or_single = xyz_im_plot(
xx,
yy,
biocircuits.aa_or_single(xx, yy, nx, ny),
xx_log,
yy_log,
biocircuits.aa_or_single(xx_log, yy_log, nx, ny),
title="two act., OR logic, single occ.",
)
bokeh.io.show(
bokeh.layouts.column(
bokeh.layouts.row(p_and, bokeh.models.Spacer(width=30), p_or),
bokeh.models.Spacer(height=20),
bokeh.layouts.row(bokeh.models.Spacer(width=300), p_or_single),
)
)
Here, purple indicates that \(f(x, y)\) is zero and yellow indicates that \(f(x, y)\) is one. With AND logic, both X and Y must have high concentrations for Z to be expressed. Conversely, for OR logic, X or Y or both can be in high concentrations for Z to be expressed, but if neither is high enough, Z does not get expressed. These graphical representations of the mathematical expressions for regulation indeed match the conceptual truth tables we started with.
Logic with two repressors
Now let’s consider the case where we have two repressors, as in the C3-FFL or I2-FFL. The AND case where X and Y are both repressors is NOT X AND NOT Y.
X |
Y |
Z |
|---|---|---|
0 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
Here, either repressor (or both) can shut down gene expression.
For OR logic with two repressors, we have NOT X OR NOT Y. Its truth table is below.
X |
Y |
Z |
|---|---|---|
0 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
1 |
1 |
1 |
0 |
We might get this kind of logic if the two repressors need to work in concert, perhaps through binding interactions, to affect repression.
We can encode these two truth tables with dimensionless regulation functions
\begin{align} &\text{AND logic: } f(x,y) = \frac{1}{(1 + x^{n_x}) (1 + y^{n_y})},\\[1em] &\text{OR logic: } f(x,y) = \frac{1 + x^{n_x} + y^{n_y}}{(1 + x^{n_x}) ( 1 + y^{n_y})}. \end{align}
For single occupancy, OR logic leads to the gene always being expressed, and the regulatory function for AND logic is
\begin{align} &\text{AND logic (single occupancy): } f(x,y) = \frac{1}{1 + x^{n_x} + y^{n_y}}. \end{align}
Let’s make some plots to see how these functions look.
[53]:
p_and = xyz_im_plot(
xx,
yy,
biocircuits.rr_and(xx, yy, nx, ny),
xx_log,
yy_log,
biocircuits.rr_and(xx_log, yy_log, nx, ny),
title="two repressors, AND logic",
)
p_or = xyz_im_plot(
xx,
yy,
biocircuits.rr_or(xx, yy, nx, ny),
xx_log,
yy_log,
biocircuits.rr_or(xx_log, yy_log, nx, ny),
title="two repressors, OR logic",
)
p_and_single = xyz_im_plot(
xx,
yy,
biocircuits.rr_and_single(xx, yy, nx, ny),
xx_log,
yy_log,
biocircuits.rr_and_single(xx_log, yy_log, nx, ny),
title="two rep., OR logic, single occ.",
)
bokeh.io.show(
bokeh.layouts.column(
bokeh.layouts.row(p_and, bokeh.models.Spacer(width=30), p_or),
bokeh.models.Spacer(height=20),
p_and_single,
)
)
Logic with one activator and one repressor
Now say we have one activator (which we will designate to be X) and one repressor (which we will designate to be Y). Now, AND logic means X AND NOT Y, and OR logic means X OR NOT Y. The truth table for the AND gate is below.
X |
Y |
Z |
|---|---|---|
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
And that for the OR gate is
X |
Y |
Z |
|---|---|---|
0 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
1 |
1 |
1 |
The dimensionless regulatory functions are
\begin{align} &\text{AND logic: } f(x,y) = \frac{x^{n_x}}{(1 + x^{n_x})(1 + y^{n_y})},\\[1em] &\text{OR logic: } f(x,y) = \frac{1 + x^{n_x} + x^{n_x}y^{n_y}}{(1 + x^{n_x})(1 + y^{n_y})}. \end{align}
For single occupancy, they are
\begin{align} &\text{AND logic (single occupancy): } f(x,y) = \frac{x^{n_x}}{1 + x^{n_x} + y^{n_y}},\\[1em] &\text{OR logic (single occupancy): } f(x,y) = \frac{1 + x^{n_x}}{1 + x^{n_x} + y^{n_y}}. \end{align}
In the single occupancy case, once levels of both X and Y exceed unity (or their Hill activitation constants in dimensional units), the relative levels of the respective genes become important. Gene expression is on if Y is not too high relative to X.
Let’s look at the plots.
[54]:
p_and = xyz_im_plot(
xx,
yy,
biocircuits.ar_and(xx, yy, nx, ny),
xx_log,
yy_log,
biocircuits.ar_and(xx_log, yy_log, nx, ny),
title="X act., Y rep., AND logic",
)
p_or = xyz_im_plot(
xx,
yy,
biocircuits.ar_or(xx, yy, nx, ny),
xx_log,
yy_log,
biocircuits.ar_or(xx_log, yy_log, nx, ny),
title="X act., Y rep., OR logic",
)
p_and_single = xyz_im_plot(
xx,
yy,
biocircuits.ar_and_single(xx, yy, nx, ny),
xx_log,
yy_log,
biocircuits.ar_and_single(xx_log, yy_log, nx, ny),
title="X act., Y rep., AND, sing. occ.",
)
p_or_single = xyz_im_plot(
xx,
yy,
biocircuits.ar_or_single(xx, yy, nx, ny),
xx_log,
yy_log,
biocircuits.ar_or_single(xx_log, yy_log, nx, ny),
title="X act., Y rep., OR, sing. occ.",
)
bokeh.io.show(
bokeh.layouts.column(
bokeh.layouts.row(p_and, bokeh.models.Spacer(width=30), p_or),
bokeh.models.Spacer(height=20),
bokeh.layouts.row(p_and_single, p_or_single),
)
)
Connection to logic gates
When two “input” effectors regulate the expression of a single “output” gene, we are tempted to connect the circuit architectures to logic gates. This is both useful and dangerous.
First, we will discuss the utility. Boolean algebra is a very powerful tool in developing circuits in digital electronics, and may also be a powerful framework for designing biological circuits. Briefly, Boolean algebra deals with only trues and falses, or ones and zeros. It has three fundamental operations, conjuction (∧), disjunction (∨), and negation (¬). They are defined such that
\begin{align} &a \land b = \left\{\begin{array}{ll} 1 & \text{if } a=b=1 \\ 0 & \text{otherwise}, \end{array} \right.\\[1em] &a \lor b = \left\{\begin{array}{ll} 0 & \text{if } a=b=0 \\ 1 & \text{otherwise}, \end{array} \right.\\[1em] &\lnot a = \left\{\begin{array}{ll} 0 & \text{if } a=1 \\ 1 & \text{if } a=0. \end{array} \right. \end{align}
One could think of two activators X and Y regulating expression of a gene Z with AND logic as Z = X ∧ Y. The relation X ∧ Y has a name; it is called an AND gate. The other architectures also represent logic gates. Below is a table of the analogous logic gates and Boolean algebra expressions for the two-effector regulation architectures we have considered.
X |
Y |
regulatory logic |
idealized logic gate |
Boolean algebra |
|---|---|---|---|---|
activator |
activator |
AND |
AND |
X ∧ Y |
activator |
activator |
OR |
OR |
X ∨ Y |
repressor |
repressor |
AND |
NOR |
¬X ∧ ¬Y = ¬(X ∨ Y) |
repressor |
repressor |
OR |
NAND |
¬X ∨ ¬Y = ¬(X ∧ Y) |
activator |
repressor |
AND |
NIMPLY |
X ∧ ¬Y |
activator |
repressor |
OR |
IMPLY* |
X ∨ ¬Y |
*An IMPLY gate has a Boolean algebraic representation of ¬X ∨ Y, which we would get if we had arbitrarily chosen X to be the repressor instead of Y.
Now, let’s consider the danger in using digital logic with these circuits. While thinking digitally for these circuits has its merit (indeed, we used a giant Hill coefficient in making the images above showing the expression levels of Z as a function of X and Y concentration), we must always remember that biological circuits are more fuzzy. As an example, let’s look at how the one repressor/one activator system looks with a Hill coefficient of two.
[55]:
p_and = xyz_im_plot(
xx,
yy,
biocircuits.ar_and(xx, yy, 2, 2),
xx_log,
yy_log,
biocircuits.ar_and(xx_log, yy_log, 2, 2),
title="X act., Y rep., AND logic",
)
p_or = xyz_im_plot(
xx,
yy,
biocircuits.ar_or(xx, yy, 2, 2),
xx_log,
yy_log,
biocircuits.ar_or(xx_log, yy_log, 2, 2),
title="X act., Y rep., OR logic",
)
bokeh.io.show(bokeh.layouts.row(p_and, bokeh.models.Spacer(width=30), p_or))
This looks a lot less digital!
We are also limited by physiological realities in our use of the Hill-like function to descibe the regulatory functions of all two-input gates we can make with Boolean logic. You may notice that we are missing XOR (exactly one of X or Y is high to give high Z) and XNOR (X and Y are either both high or both low to give high Z), the two other basic two-input logic gates. We leave it to the reader to work out what the Hill-like regulatory functions \(f(x,y)\) for these gates would be following the prescription we have been using. Also think about how XOR- or XNOR-like logic might occur physiologically and why we usually do not use the Hill-like functions we are employing here in those cases. You can explore these ideas in Problem 4.4.
Regulatory functions and their derivatives
As we proceed through analysis of biological circuits, we will use the regulatory functions we have just derived, in addition to activating and repressive Hill functions, extensively. For convenience, these functions and their derivatives with respect to \(x\) and \(y\) are in Appendix D.
The biocircuits package and regulatory functions
The biocircuits package contains the regulatory functions we have just described. The available regulatory functions and call signatures are:
Repressive Hill function:
biocircuits.rep_hill(x, n)Activating Hill function:
biocircuits.act_hill(x, n)Two activators with AND logic:
biocircuits.aa_and(x, y, nx, ny)Two activators with OR logic:
biocircuits.aa_or(x, y, nx, ny)Two activators with AND logic, single occupancy:
biocircuits.aa_or_single(x, y, nx, ny)Two repressors with AND logic:
biocircuits.rr_and(x, y, nx, ny)Two repressors with OR logic:
biocircuits.rr_or(x, y, nx, ny)Two repressors with AND logic, single occupancy:
biocircuits.rr_and_single(x, y, nx, ny)One activator and one repressor with AND logic:
biocircuits.ar_and(x, y, nx, ny)One activator and one repressor with OR logic:
biocircuits.ar_or(x, y, nx, ny)One activator and one repressor with AND logic, single occupancy:
biocircuits.ar_and_single(x, y, nx, ny)One activator and one repressor with OR logic, single occupancy:
biocircuits.ar_or_single(x, y, nx, ny)
It is important to note that the inputs x and y are dimensionless. In the case of one activator and one repressor, x is always assumed to the the concentration of the activator and y that of the repressor.
The code comprising the functions are simply expressions of the mathematical equations given above using Numpy arrays. For example, the contents of biocircuits.rr_and() is given below.
def rr_and(x, y, nx, ny):
"""Dimensionless production rate for a gene regulated by two
repressors with AND logic in the absence of leakage.
Parameters
----------
x : float or NumPy array
Concentration of first repressor.
y : float or NumPy array
Concentration of second repressor.
nx : float
Hill coefficient for first repressor.
ny : float
Hill coefficient for second repressor.
Returns
-------
output : NumPy array or float
1 / (1 + x**nx) / (1 + y**ny)
"""
return 1 / (1 + x ** nx) / (1 + y ** ny)
These functions were used in generating the plots above, and we will use them going forward in this chapter as we numerically evaluate the dynamical equations of FFLs and beyond.
Dynamical equations for FFLs
To analyze the C1-FFL (or any of the other FFLs), in response to changes in the input X, we can write a generic system of ODEs for the concentrations of Y and Z. We know that Y is either activated or repressed by X and itself experiences degradation. We define a dimensionless function \(f_y(x/k_{xy}; n_{xy})\) to describe the activating or repressive Hill function for the regulation of X by Y. We have used the notation that \(n_{ij}\) is the Hill coefficient for j regulated by i, with \(k_{ij}\) similarly defined. To be explicit, if X activates Y, then
\begin{align} f_y(x/k_{xy}; n_{xy}) = \frac{(x/k_{xy})^{n_{xy}}}{1 + (x/k_{xy})^{n_{xy}}}, \end{align}
and if X represses Y, then
\begin{align} f_y(x/k_{xy}; n_{xy}) = \frac{1}{1 + (x/k_{xy})^{n_{xy}}}. \end{align}
The dynamical equation for \(y\) for either activating or repressive action by X is
\begin{align} \frac{\mathrm{d}y}{\mathrm{d}t} &= \beta_y\,f_y(x/k_{xy}; n_{xy}) - \gamma_y y. \end{align}
Similarly, we define the dimensionless function \(f_z(x/k_{xz}, y/k_{yz}; n_{xz}, n_{yz})\) to describe the regulation in expression of Z by X and Y. This have any of the functional forms we have listed above for activation/repression pairs and AND/OR logic. The dynamical equation for \(z\) is then
\begin{align} \frac{\mathrm{d}z}{\mathrm{d}t} &= \beta_z\,f_z(x/k_{xz}, y/k_{yz}; n_{xz}, n_{yz}) - \gamma_z z. \end{align}
We can nondimensionalize these equations by choosing
\begin{align} t &= \tilde{t} / \gamma_y, \\[1em] x &= k_{xz}\,\tilde{x},\\[1em] y &= k_{yz}\,\tilde{y},\\[1em] z &=z_d\,\tilde{z}, \end{align}
where \(z_d\) is as of yet unspecified. Inserting these expressions into the dynamical equations gives
\begin{align} \gamma_y k_{yz}\,\frac{\mathrm{d}\tilde{y}}{\mathrm{d}\tilde{t}} &= \beta_y\,f_y\left(\frac{k_{xz}}{k_{xy}}\,\tilde{x}; n_{xy}\right) - \gamma_y k_{yz} \tilde{y},\\[1em] \gamma_y z_d\,\frac{\mathrm{d}\tilde{z}}{\mathrm{d}\tilde{t}} &= \beta_z\,f_z(\tilde{x}, \tilde{y}; n_{xz}, n_{yz}) - \gamma_z z_0 \tilde{z}. \end{align}
If we conveniently define \(z_d = \beta_z/\gamma_z\), then the dynamical equations become
\begin{align} \frac{\mathrm{d}\tilde{y}}{\mathrm{d}\tilde{t}} &= \beta\,f_y\left(\kappa\tilde{x}; n_{xy}\right) - \tilde{y},\\[1em] \gamma^{-1}\,\frac{\mathrm{d}\tilde{z}}{\mathrm{d}\tilde{t}} &= f_z(\tilde{x}, \tilde{y}; n_{xz}, n_{yz}) - \tilde{z}, \end{align}
where we have defined
\begin{align} &\beta = \frac{\beta_y}{\gamma_y k_{yz}},\\[1em] &\gamma = \frac{\gamma_z}{\gamma_y}, \\[1em] &\kappa = \frac{k_{xz}}{k_{xy}}. \end{align}
In addition to the Hill coefficients, these dimensionless parameters complete the parameter set of a dynamical system describing an FFL. Each has a physical meaning. The parameter \(\beta\) is the dimensionless unregulated steady state level of \(y\), \(\gamma\) is the ratio of the decay rates of Z and Y, and \(\kappa\) is the ratio of the amounts of X that are necessary to regulate Z and Y.
Henceforth, we will work with these dimensionless equations and will drop the tildes for notational convenience.
Note that these are dynamical equations for any FFL. It is not much more difficult to consider numerical solutions of all FFLs that one individually, so we develop functions in Technical Appendix 4a for that purpose. The functions are available in the biocircuits.apps module.
The C1-FFL circuit enables sign-sensitive delay
Now that we have laid the computational groundwork, we will proceed to an analysis of the first of the two over-represented FFLs, the C1-FFL. For reference, here again are the dimensionless dynamical equations:
\begin{align} \frac{\mathrm{d}y}{\mathrm{d}t} &= \beta\,\frac{(\kappa x)^{n_{xy}}}{1 + (\kappa x)^{n_{xy}}} - y, \\[1em] \gamma^{-1}\frac{\mathrm{d}z}{\mathrm{d}t} &= \frac{x^{n_{xz}} y^{n_{yz}}}{(1 + x^{n_{xz}})\,(1+ y^{n_{yz}})} - z. \end{align}
Now, let us look at the dynamics for a sudden step up and step down in X. We will use dimensionless parameter values \(\beta = 5\), \(\gamma = \kappa = 1\), \(n_{xy} = n_{yz} = 3\), and \(n_{xy} = 5\).
[56]:
# Parameter values
beta = 5
gamma = 1
kappa = 1
n_xy, n_yz = 3, 3
n_xz = 5
# Plot
p, _, _ = biocircuits.apps.plot_ffl(
beta, gamma, kappa, n_xy, n_xz, n_yz, ffl="c1", logic="and"
)
bokeh.io.show(p)
Notice that there is a time delay for production of Z upon stimulation with X. This is a result of the AND logic. Though X has immediately come up, we have to wait for the signal to pass through Y for Z to come up. However, there is no delay when the signal X is turned off. The z curve responds immediately. This off-response is perhaps more apparent if we normalize the concentrations.
[57]:
p, _, _ = biocircuits.apps.plot_ffl(
beta, gamma, kappa, n_xy, n_xz, n_yz, ffl="c1", logic="and", normalized=True,
)
bokeh.io.show(p)
Here, the on-delay is more apparent, as is the fact that both Y and Z have their levels immediately decrease when the X stimulus is removed. So, we have arrived at a design principle: The C1-FFL with AND logic has an on-delay, but no off-delay.
The magnitude of the delay can be tuned with κ
How might we get a longer delay? If we decrease \(\kappa = k_{xz}/k_{yz}\), we are increasing the disparity between the threshold levels needed to turn on gene expression. This should result in a longer time delay. Let’s try it for \(\kappa = 0.1\).
[58]:
# Update parameter
kappa = 0.1
p, _, _ = biocircuits.apps.plot_ffl(
beta, gamma, kappa, n_xy, n_xz, n_yz, ffl="c1", logic="and", normalized=True,
)
bokeh.io.show(p)
Indeed, the delay is longer with small κ. We can quantify how the delay changes with κ by plotting how long it takes for the \(z\) level to rise to ten percent of its steady state value for various values of κ.
[59]:
tau = []
kappa_vals = np.logspace(-1, 2, 200)
# Finer time points
t_ = np.linspace(0, 20, 5000)
for kappa in kappa_vals:
# Solve for the dynamics
yz = biocircuits.apps.solve_ffl(
beta, gamma, kappa, n_xy, n_xz, n_yz, "c1", "and", t_, np.inf, 1
)
# Determine threshold value
z_thresh = yz[-1, 1] * 0.1
# Find where the threshold is crossed
tau.append(t_[np.searchsorted(yz[:,1], z_thresh)])
p = bokeh.plotting.figure(
frame_width=400,
frame_height=250,
x_axis_type="log",
x_axis_label="κ",
y_axis_label="time to 10% of steady state",
x_range=[0.1, 100],
y_range=[0, 1.25],
)
p.scatter(kappa_vals, tau)
bokeh.io.show(p)
The delay does not change substantially, only about a factor of three over many orders of magnitude of κ, but it does change nonetheless.
The delay does not require ultrasensitivity
We might think that ultrasensitivity is required for the delay, but it is not, as seen by the calculation below with \(n_{xy} = n_{xz} = n_{yz} = 1\).
[60]:
# No ultrasensitivity
n_xy, n_xz, n_yz = 1, 1, 1
p, _, _ = biocircuits.apps.plot_ffl(
beta, gamma, kappa, n_xy, n_xz, n_yz, ffl="c1", logic="and", normalized=True,
)
bokeh.io.show(p)
Without ultrasensitivity, the delay is shorter, but present nonetheless. This is because with AND logic, the expression of Z still has to wait for Y to get high enough to begin producing Z at an appreciable level, regardless of how ultrasensitive the dynamics are.
The C1-FFL with AND logic and filter out short pulses
Now, let’s see what happens if we have a shorter pulse. The delay feature of the C1-FFl should filter out pulses that are shorter than the time scale of the delay.
[61]:
# Shorter pulse
t = np.linspace(0, 1, 200)
t_step_down = 0.1
# Reset kappa and ultrasensitivity
kappa = 1
n_xy, n_xz, n_yz = 3, 5, 3
p, _, _ = biocircuits.apps.plot_ffl(
beta,
gamma,
kappa,
n_xy,
n_xz,
n_yz,
ffl="c1",
logic="and",
t=t,
t_step_down=t_step_down,
normalized=False,
)
bokeh.io.show(p)
The shorter pulse is ignored in the Z-response because of the delay.
The sign-sensitivity of the delay is reversed with OR logic
We will now investigate the response of the circuit to the same stimulus, except with OR logic.
[62]:
p, _, _ = biocircuits.apps.plot_ffl(
beta, gamma, kappa, n_xy, n_xz, n_yz, ffl="c1", logic="or", normalized=False,
)
bokeh.io.show(p)
Now we see that both Y and Z immediately start being produced upon stimulus, but there is a delay in the decrease of Z when the stimulus is removed. As with the AND logic, this is perhaps more easily seen with normalized concentrations.
[63]:
p, _, _ = biocircuits.apps.plot_ffl(
beta, gamma, kappa, n_xy, n_xz, n_yz, ffl="c1", logic="or", normalized=True,
)
bokeh.io.show(p)
The level of Z in a C1-FFL with OR logic does respond to a pulse in X, but, analogously to the case with AND logic, it ignores a quick decrease and increase in X. We will not show that calculation here, but encourage you to do it yourself or explore that scenario with the dashboard below.
Sign sensitive delay is observed experimentally
The arabinose and lac systems in E. coli are both turned on by cyclic AMP (cAMP), which stimulates production of CRP, but they have different architectures, shown below.
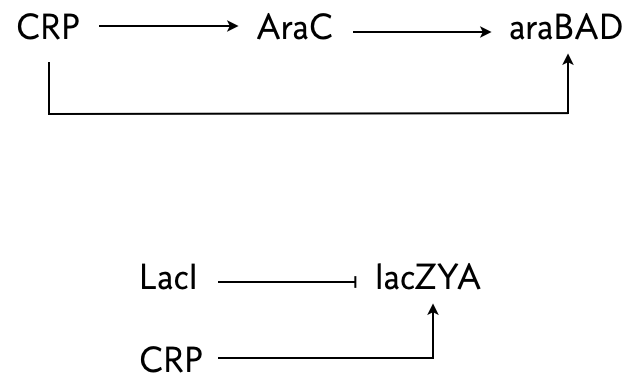
In both systems where multiple species regulate one, AND logic is employed.
Mangan an coworkers (J. Molec. Biol., 2003) performed an experiment where they put a fluorescent reporter under control of the products of these two systems, araBAD and lacZYA, respectively. In the lac system, IPTG was also present, so LacI was inhibited. Thus, lacZYA production was directly activated by CRP. Conversely, the arabinose system is a C1-FFL.
They measured the fluorescent intensity in cells that were suddenly exposed to cAMP. The response of these two systems to the sudden jump in cAMP is shown in the left plot below.
[64]:
# Plot data digitized from Mangan, et al., J. Molec. Biol., 2003
# https://doi.org/10.1016/j.jmb.2003.09.049
t_araBAD_on = np.array([
6.44, 7.55, 8.65, 10. , 10.98, 12.21, 13.31, 14.42, 15.4 ,
16.75, 17.98, 19.14, 20.31, 21.6 , 22.64, 23.56, 24.6 , 25.34,
26.26, 27.18, 27.98, 28.77, 29.57, 30.55, 31.35, 32.09, 33.19,
34.79, 36.2 , 37.55, 38.83, 40.06, 41.29, 42.88])
t_araBAD_off = np.array([
6.18, 7.16, 8.77, 9.69, 10.48, 11.47, 12.63, 14.11, 15.72,
17.01, 18.24, 18.55, 19.72, 21.13, 22.42, 23.96, 25.49, 26.97,
28.26, 29.74, 30.54, 31.46, 32.94, 34.05, 35.03, 35.83, 36.94,
37.68, 38.97, 40.57, 42.3 , 43.96])
t_lacZYA_on = np.array([
6.5 , 7.48, 8.22, 9.45, 10.98, 12.33, 13.74, 15.28, 16.69,
18.04, 19.39, 20.8 , 22.09, 23.44, 24.91, 26.13, 27.55, 28.71,
30.06, 31.72])
t_lacZYA_off = np.array([
6.05, 7.78, 8.89, 10. , 10.55, 11.72, 12.7 , 13.25, 14.54,
15.59, 16.7 , 18.25, 19.41, 20.64, 21.75, 22.92, 24.27, 25.19,
26.11, 27.41, 28.33, 29.62, 30.66, 31.89, 32.88, 33.86, 35.22,
36.57, 37.8 , 38.97, 39.64, 41.12, 42.47, 44.07])
x_araBAD_on = np.array([
0.02, 0.01, 0. , 0. , 0. , 0.01, 0.02, 0.03, 0.04, 0.04, 0.04,
0.04, 0.04, 0.04, 0.05, 0.06, 0.08, 0.09, 0.1 , 0.11, 0.13, 0.14,
0.15, 0.17, 0.18, 0.2 , 0.22, 0.25, 0.29, 0.33, 0.38, 0.42, 0.46,
0.49])
x_araBAD_off = np.array([
1. , 0.99, 0.97, 0.95, 0.91, 0.88, 0.86, 0.86, 0.84, 0.83, 0.82,
0.79, 0.77, 0.74, 0.7 , 0.68, 0.64, 0.61, 0.58, 0.57, 0.55, 0.52,
0.51, 0.49, 0.47, 0.46, 0.45, 0.44, 0.41, 0.4 , 0.38, 0.36])
x_lacZYA_on = np.array([
0.02, 0.03, 0.04, 0.05, 0.06, 0.09, 0.11, 0.13, 0.15, 0.17, 0.2 ,
0.23, 0.26, 0.29, 0.32, 0.34, 0.38, 0.4 , 0.44, 0.48])
x_lacZYA_off = np.array([
0.99, 0.98, 0.96, 0.95, 0.93, 0.9 , 0.88, 0.86, 0.84, 0.84, 0.84,
0.83, 0.8 , 0.77, 0.75, 0.71, 0.69, 0.66, 0.65, 0.63, 0.6 , 0.58,
0.55, 0.53, 0.5 , 0.49, 0.47, 0.45, 0.43, 0.4 , 0.38, 0.35, 0.33,
0.3 ])
p1 = bokeh.plotting.figure(
frame_height=250,
frame_width=300,
x_axis_label='time (min)',
y_axis_label="normalized level",
title="step: on",
toolbar_location="above",
)
p1.scatter(t_lacZYA_on, x_lacZYA_on, color=colors[0])
p1.scatter(t_araBAD_on, x_araBAD_on, color=colors[1])
p2 = bokeh.plotting.figure(
frame_height=250,
frame_width=300,
x_axis_label='time (min)',
y_axis_label="normalized level",
title="step: off",
toolbar_location="above",
)
p2.scatter(t_lacZYA_off, x_lacZYA_off, color=colors[0], legend_label="lacZYA")
p2.scatter(t_araBAD_off, x_araBAD_off, color=colors[1], legend_label='araBAD')
bokeh.io.show(bokeh.layouts.row(p1, bokeh.layouts.Spacer(width=30), p2))
While the lac system responds immediately, the arabinose system exhibits a lag before responding. This is indicative of a time delay for a step on in the stimulus for a C1-FFL. Conversely, after these systems come to steady state and are subjected to a sudden decrease in cAMP, both the arabinose and lac systems respond immediately, without delay, which is also expected from a C1-FFL with AND logic.
Kalir and coworkers (Kalir, et al., 2005) did a similar experiment with another C1-FFL circuit found in E. coli, this time with OR logic. A circuit that regulates flagella formation is a “decorated” C1-FFL, shown below. We say it is decorated because the “Y” gene, in this case FliA, is also autoregulated. Importantly, the regulation of FliL by FliA and FlhDC is governed by OR logic.
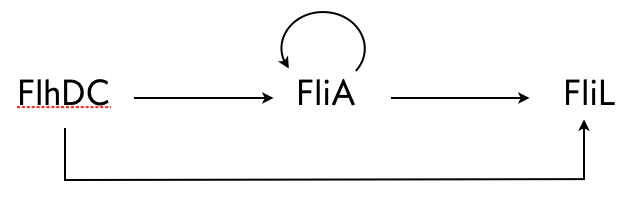
Kalir and coworkers used engineered cells in which the FlhDC gene was under control of a promoter which could be induced with L-arabinose, a chemical inducer. The gene product FliL was altered to be fused to GFP to enable fluorescent monitoring of expression levels. To consider a circuit where FlhDC directly activates FliL, Kalir and coworkers used mutant E. coli cells in which the fliA gene was deleted.
Because of the OR logic, we would expect that a sudden increase in FlhDC would result in both the wild type and mutant cells to respond at the same time, that is with no delay. Fluorescence traces from these experiments are shown in the left plot, below.
[65]:
# Plot data digitized from Kalir, et al., Mol. Sys. Biol., 2005
# https://doi.org/10.1038/msb4100010
t_deleted_on = np.array([
0.56, 7.89, 15.61, 23.53, 31.06, 38.59, 46.32, 54.05,
61.98, 69.33, 77.08, 84.63, 93.14, 100.12, 107.85, 115.59,
123.33, 131.06, 138.61])
t_deleted_off = np.array([
0.45, 7.63, 15.41, 23.2 , 30.8 , 38.6 , 46.2 , 54.01,
61.81, 69.21, 76.81, 84.61, 92.21, 100.01, 107.61, 115.4 ,
123.4 , 130.79, 138.39, 145.99])
t_present_on = np.array([
15.79, 23.51, 31.43, 38.96, 46.89, 54.62, 62.36, 69.91,
77.85, 85.6 , 93.15, 100.69, 108.24, 115.97, 123.52, 131.45,
138.99])
t_present_off = np.array([
1.25, 8.04, 15.64, 23.24, 31.05, 38.87, 46.68, 54.5 ,
62.11, 69.52, 77.32, 85.13, 92.73, 100.32, 107.92, 115.91,
123.3 , 131.09, 138.48, 146.07])
x_deleted_on = np.array([
0.09, 0.07, 0.06, 0.06, 0.06, 0.07, 0.09, 0.13, 0.19, 0.28, 0.38,
0.47, 0.55, 0.64, 0.71, 0.78, 0.83, 0.89, 0.94])
x_deleted_off = np.array([
1. , 0.92, 0.85, 0.8 , 0.77, 0.74, 0.72, 0.7 , 0.68, 0.65, 0.62,
0.59, 0.57, 0.54, 0.51, 0.46, 0.43, 0.39, 0.36, 0.33])
x_present_on = np.array([
0. , 0. , 0.01, 0.02, 0.05, 0.1 , 0.17, 0.26, 0.36, 0.47, 0.55,
0.62, 0.69, 0.75, 0.81, 0.88, 0.94])
x_present_off = np.array([
1. , 0.95, 0.91, 0.9 , 0.9 , 0.9 , 0.92, 0.92, 0.92, 0.92, 0.9 ,
0.88, 0.86, 0.83, 0.78, 0.73, 0.68, 0.64, 0.59, 0.54])
p1 = bokeh.plotting.figure(
frame_height=250,
frame_width=300,
x_axis_label='time (min)',
y_axis_label="normalized level",
title="step: on",
toolbar_location="above",
)
p1.scatter(t_deleted_on, x_deleted_on, color=colors[0])
p1.scatter(t_present_on, x_present_on, color=colors[1])
p2 = bokeh.plotting.figure(
frame_height=250,
frame_width=300,
x_axis_label='time (min)',
y_axis_label="normalized level",
title="step: off",
toolbar_location="above",
)
p2.scatter(t_deleted_off, x_deleted_off, color=colors[0], legend_label="FliA deleted")
p2.scatter(t_present_off, x_present_off, color=colors[1], legend_label='FliA present')
p2.legend.location = 'bottom_left'
bokeh.io.show(bokeh.layouts.row(p1, bokeh.layouts.Spacer(width=30), p2))
Both strains show a delay, which is due to waiting for FlhDC to be activated, but both come on at the same time. Conversely, after the inducer is removed and FlhDC levels go down, the system with the wild type C1-FFL circuit shows a delay before the FliL levels drop off, while the mutant does not. This demonstrates the sign-sensitivity with OR logic.
The I1-FFL with AND logic is a pulse generator
We now turn our attention to the other over-represented circuit, the I1-FFL. As a reminder, here is the structure of the circuit.
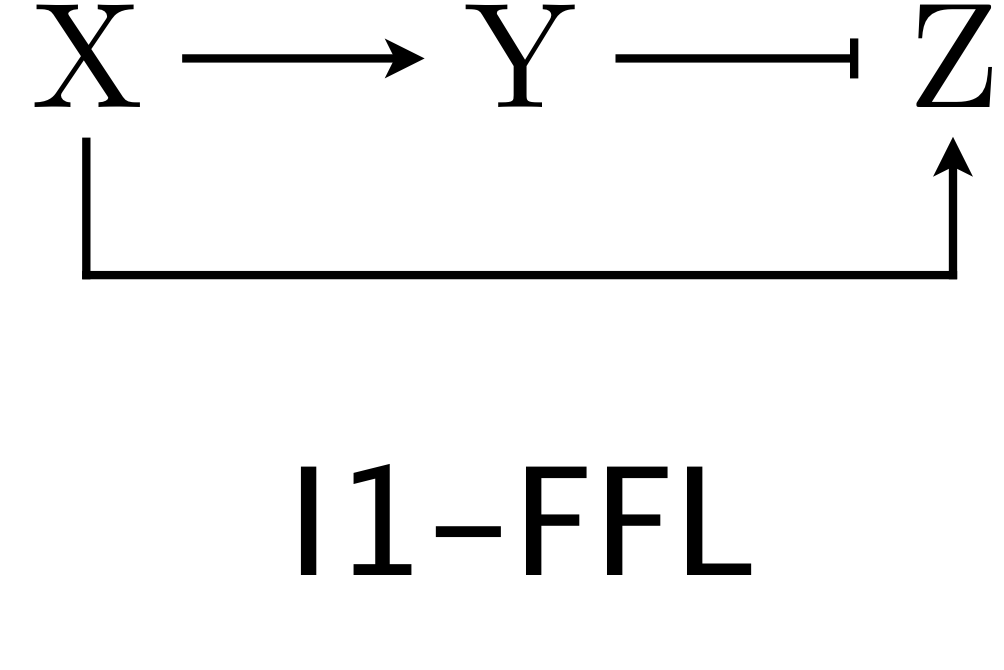
X activates Y and Z, but Y represses Z. We can use the expressions for production rate under AND and OR logic for one activator/one repressor that we showed above in writing down our dynamical equations. Here, we will consider AND logic. The dimensionless dynamical equations are
\begin{align} \frac{\mathrm{d}y}{\mathrm{d}t} &= \beta\,\frac{(\kappa x)^{n_{xy}}}{1+(\kappa x)^{n_{xy}}} - y,\\[1em] \gamma^{-1}\,\frac{\mathrm{d}z}{\mathrm{d}t} &= \frac{x^{n_{xz}}}{(1 + x^{n_{xz}})\,(1 + y^{n_{yz}})} - z. \end{align}
In our first analysis of this circuit, we will investigate the response in Z to a sudden, sustained step in stimulus X. We will choose \(\gamma = 10\), which means that the dynamics of Z are faster than Y.
[66]:
# Parameter values
beta = 5
gamma = 10
kappa = 1
n_xy, n_yz = 3, 3
n_xz = 5
t = np.linspace(0, 10, 200)
# Set up and solve
p, _, _ = biocircuits.apps.plot_ffl(
beta,
gamma,
kappa,
n_xy,
n_xz,
n_yz,
ffl="i1",
logic="and",
t=t,
t_step_down=np.inf,
normalized=False,
)
bokeh.io.show(p)
We see that Z pulses up and then falls down to its steady state value. This is because the presence X leads to production of Z due to its activation. X also leads to the increase in Y, and once enough Y is present, it can start to repress Z. This brings the Z level back down toward a new steady state where the production rate of Z is a balance between activation by X and repression by Y. Thus, the I1-FFL with AND logic is a pulse generator.
The I1-FFL with AND logic gives an accelerated response
Let us compare the response of an I1-FFL being suddenly turned on (by a step in X) to an unregulated circuit that achieves the same steady state. Recall that the dimensionless dynamics for the unregulated circuit (that is, X ⟶ Z, the circuit in the absence of Y) follow
\begin{align} z(t) = 1 - \mathrm{e}^{-t}. \end{align}
If we plot the normalized I1-FFL together with the unregulated response, we see that the I1-FFl makes it to the steady state faster, though it overshoots and then relaxes.
[ ]:
p, _, _ = biocircuits.apps.plot_ffl(
beta,
gamma,
kappa,
n_xy,
n_xz,
n_yz,
ffl="i1",
logic="and",
t=t,
t_step_down=np.inf,
normalized=True,
)
# Unregulated dynamics
p.line(
t, 1 - np.exp(-t), line_width=2, color=colors[4], legend_label="unregulated",
)
bokeh.io.show(p)
So, we have another design principle, The I1-FFL with AND logic has a faster response time than an unregulated circuit.
The accelerated response of the I1-FFL is observed experimentally
Mangan and coworkers (Mangan, et al., 2006) investigated an I1-FFL circuit that E. coli uses in its galactose utilization system. The circuit is shown below.

As the “X” gene in this I1-FFL is CRP, the circuit is induced by sudden addition of cAMP, as in the arabinose and lactose circuits above. Mangan and coworkers investigated the response of the wild type circuit, as well as a mutant circuit where galS was deleted. This latter circuit lacks the feed forward loop, and the production of galETK is directly regulated by CRP.
In their experiment, the galE promoter was engineering to express GFP so they could monitor the dynamics of the circuit with fluorescence. The result is shown below.
[ ]:
# Plot data digitized from Mangan, et al., J. Molec. Biol., 2006
# https://doi.org/10.1016/j.jmb.2005.12.003
t_wt = np.array([
0.07, 0.39, 0.71, 0.94, 1.2 , 1.45, 1.67, 1.9 , 2.14, 2.35, 2.55,
2.74, 2.89, 3.05])
t_mut = np.array([
0.05, 0.29, 0.58, 0.83, 1.05, 1.28, 1.53, 1.75, 1.96, 2.17, 2.37])
x_wt = np.array([
0.04, 0.56, 1.11, 1.53, 1.73, 1.78, 1.67, 1.44, 1.3 , 1.2 , 1.11,
1.05, 1. , 1. ])
x_mut = np.array([
0.04, 0.16, 0.32, 0.46, 0.5 , 0.56, 0.62, 0.68, 0.71, 0.75, 0.79])
p = bokeh.plotting.figure(
frame_height=250,
frame_width=350,
x_axis_label='time (cell divisions)',
y_axis_label="normalized level",
)
p.scatter(t_wt, x_wt, color=colors[0], legend_label="wild type")
p.scatter(t_mut, x_mut, color=colors[1], legend_label="galS mutant")
p.legend.location = "bottom_right"
bokeh.io.show(p)
We see that indeed the wild type I1-FFL architecture speeds up the response to the cAMP input, complete with the overshoot we expect from an I1-FFL circuit.
A dashboard for exploring FFLs
The biocircuits package has apps to explore properties of some specific circuits. To explore FFLs, you and use the FFL app. (The apps submodule of biocircuits must be imported separately.) You can use this app to explore how the C1-FFL and I1-FFL studied in this chapter responds to steps up and down in input. You can also explore the dynamics of the other six FFLs. We encourage you to look at the code in the biocircuits
package that generates the app so you can see how the dashboard is build.
Note that if you are viewing the code cell below in the static HTML rendering of this notebook, it will not appear.
[ ]:
if interactive_python_plots:
app = biocircuits.apps.ffl_app()
bokeh.io.show(app, notebook_url=notebook_url)
References
Alon, U., Network motifs: Theory and experimental approaches, Nat. Rev. Genet., 8, 450–461, 2007. (link)
Bintu, L., et al., Transcriptional regulation by the numbers: models, Curr. Op. Genet. Dev., 15, 116–124, 2005.(link)
Kalir, S., Mangan, S., and Alon, U., A coherent feed-forward loop with a SUM input function prolongs flagella expression in Escherichia coli, Molec. Sys. Biol., 1, 2005.006, 2005. (link)
Mangan, S., et al., The incoherent feed-forward loop accelerates the response-time of the gal system of Escherichia coli, J. Molec. Biol., 356, 1073–1081, 2006. (link)
Milo, R., et al., Network motifs: Simple building blocks of complex networks, Science, 298, 824–827, 2002. (link)
Milo, R., et al., Superfamilies of evolved and designed networks, Science, 303, 1538–1542, 2004.(link)
Newman, M. E. J., Strogatz, S. H., and Watts, D. J., Random graphs with arbitrary degree distributions and their applications, Phys. Rev. E, 64, 026118, 2001. (link)
Shen-Orr, S. S., et al., Network motifs in the transcriptional regulation network of Escherichia coli, Nature Genetics, 31, 64–68, 2002. (link)
Problems
Technical appendix
Computing environment
[ ]:
%load_ext watermark
%watermark -v -p numpy,scipy,bokeh,biocircuits,jupyterlab
The watermark extension is already loaded. To reload it, use:
%reload_ext watermark
Python implementation: CPython
Python version : 3.10.10
IPython version : 8.12.0
numpy : 1.23.5
scipy : 1.10.1
bokeh : 3.1.0
biocircuits: 0.1.11
jupyterlab : 3.5.3